Predicting New York Times Picks from Comment Metadata
Yixue Wang, Hanlin Li, Katya Borgos-Rodriguez
{yixuewang2022, hanlinli2022, katyaborgos-rodriguez2022}
@ u.northwestern.edu
In our project, we built classification models to predict whether or not a comment left by a reader on an online article was picked by editors (i.e., ‘Times Pick’) of the American newspaper, The New York Times (NYT). We sampled 100,000 posts from a dataset that was collected in an ongoing research project and examined comment metadata including reply count, recommendation count and sentiment scores. Several machine learning algorithms (Naive Bayes, SVM, Random Forest, LinearSVC, and Logistic Regression) were tested before concluding that a stacking model achieved the best average precision score, 0.33.
![Motivation [100%x75]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22348%22%20height%3D%22225%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20348%20225%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_163cb9a98cf%20text%20%7B%20fill%3A%23eceeef%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A17pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_163cb9a98cf%22%3E%3Crect%20width%3D%22348%22%20height%3D%22225%22%20fill%3D%22%2355595c%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%22116.7265625%22%20y%3D%22120.3%22%3EThumbnail%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
Managing and moderating online news comments at scale can be challenging and overwhelming for editors. A previous study shows that picking a high-quality comment often requires many considerations from editors that hard-coded rules could not resolve. The classification model makes it possible for the researchers to understand the social impacts of the picks by evaluating the comment quality trends of individual users and promotes more engagements in the online community in the long term and help editors to moderate online comments at scale.
![Dataset [100%x75]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22348%22%20height%3D%22225%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20348%20225%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_163cb9a98d3%20text%20%7B%20fill%3A%23eceeef%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A17pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_163cb9a98d3%22%3E%3Crect%20width%3D%22348%22%20height%3D%22225%22%20fill%3D%22%2355595c%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%22116.7265625%22%20y%3D%22120.3%22%3EThumbnail%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
The source of our data is The New York Times Community API. We have sampled 100,000 posts, dating from March 21, 2015 to April 2, 2015, from a dataset that was collected in an ongoing research project. Only 2,031 of the comments in this set are NYT picks; thus, the data was a very imbalanced dataset. The data was partitioned such that there was a training set of 90,000, and a validation dataset of 10,000. Furthermore, we sampled another 50,000 posts for the purpose of testing our code.
![Solution [100%x75]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22348%22%20height%3D%22225%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20348%20225%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_163cb9a98d2%20text%20%7B%20fill%3A%23eceeef%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A17pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_163cb9a98d2%22%3E%3Crect%20width%3D%22348%22%20height%3D%22225%22%20fill%3D%22%2355595c%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%22116.7265625%22%20y%3D%22120.3%22%3EThumbnail%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
We approached this problem by putting our dataset through several machine learning algorithms available in the scikit-learn library, including:
- Naive Bayes
- Support Vector Machine (SVM)
- Random Forest
- LinearSVC
- Logistic Regression
The features that we used are:
- Reply count
- Recommendation count (i.e., how many times the post is voted as ‘recommended’ by the community)
- Negative and positive sentiment score computed by NLTK’s SentimentAnalyzer
- Word count
- Hour when the comment was created
- Tf-idf vector from the comment
![Training and Testing [100%x75]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22348%22%20height%3D%22225%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20348%20225%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_163cb9a98d4%20text%20%7B%20fill%3A%23eceeef%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A17pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_163cb9a98d4%22%3E%3Crect%20width%3D%22348%22%20height%3D%22225%22%20fill%3D%22%2355595c%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%22116.7265625%22%20y%3D%22120.3%22%3EThumbnail%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
As mentioned in the 'Dataset' section, our dataset was imbalanced. In order to mitigate this problem, we applied balanced bagging classifier from imbalanced-learn library, which randomly undersamples the non-picks and train the processed balanced data for 10 different times to improve the performance.
Training and testing using the features and algorithms described in the previous sections, we obtained f1-score of around 0.2 and average precision score of around 0.2. Among all of the classifiers, Random Forest and Logistic Regression achieved the highest average precision score (0.29 and 0.25, respectively). Figures 1 and 2 are the precision-recall plots for these two models.
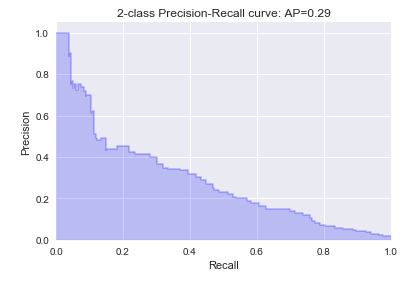
Figure 1. Precision-Recall plot, Random Forest (the number of trees = 400, class_weight = 'balanced').
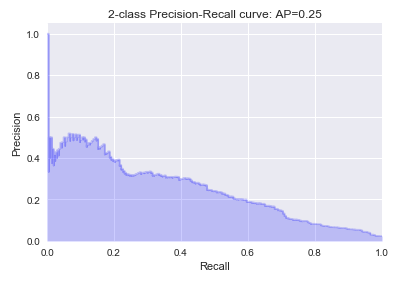
Figure 2. Precision-Recall plot, Logistic Regression using BaggingClassifier BalancedBaggingClassifier(base_estimator= LogisticRegression(), replacement = True).
After running all the models mentioned before, there is another technique that we tried in order to improve the performance - stacking from mlxtend library. Base models in the stacking model included all the algorithms we tried before and the probabilities produced by these base models were used as meta-features, and BalancedBaggingClassifier with base model as logistic regression was used as the meta model to build a stacking model. The new stacking model achieved the best average precision score, 0.33. The precision-recall plot is shown in Figure 3. The details of preprocessing data, feature engineering and and models comparisons are all covered in the Jupyter Notebook.
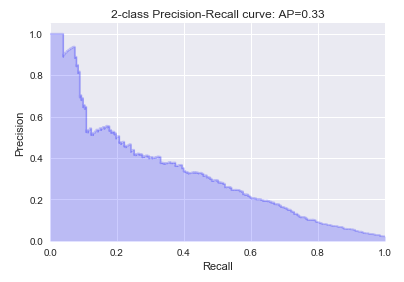
Figure 3. Precision-Recall plot, StackingClassifier.
![Team [100%75]](data:image/svg+xml;charset=UTF-8,%3Csvg%20width%3D%22348%22%20height%3D%22225%22%20xmlns%3D%22http%3A%2F%2Fwww.w3.org%2F2000%2Fsvg%22%20viewBox%3D%220%200%20348%20225%22%20preserveAspectRatio%3D%22none%22%3E%3Cdefs%3E%3Cstyle%20type%3D%22text%2Fcss%22%3E%23holder_163cb9a98d6%20text%20%7B%20fill%3A%23eceeef%3Bfont-weight%3Abold%3Bfont-family%3AArial%2C%20Helvetica%2C%20Open%20Sans%2C%20sans-serif%2C%20monospace%3Bfont-size%3A17pt%20%7D%20%3C%2Fstyle%3E%3C%2Fdefs%3E%3Cg%20id%3D%22holder_163cb9a98d6%22%3E%3Crect%20width%3D%22348%22%20height%3D%22225%22%20fill%3D%22%2355595c%22%3E%3C%2Frect%3E%3Cg%3E%3Ctext%20x%3D%22116.7265625%22%20y%3D%22120.3%22%3EThumbnail%3C%2Ftext%3E%3C%2Fg%3E%3C%2Fg%3E%3C%2Fsvg%3E)
Yixue Wang
Ph.D. Student in Technology and Social Behavioryixuewang2022 [at] u.northwestern.edu
Hanlin Li
Ph.D. Student in Technology and Social Behaviorhanlinli2022 [at] u.northwestern.edu
Katya Borgos-Rodriguez
Ph.D. Student in Technology and Social Behaviorkatyaborgos-rodriguez2022 [at] u.northwestern.edu